How to deploy your knowledge graph in a graph database with Ontop
Many people build a knowledge graph by moving and transforming existing data into a graph database. This approach is also known as knowledge graph materialization.
During the past decade, Ontop has become a reference open-source solution for materializing knowledge graphs from relational data sources in large organizations.
In this article, we present two ways to materialize your knowledge graph using Ontop.
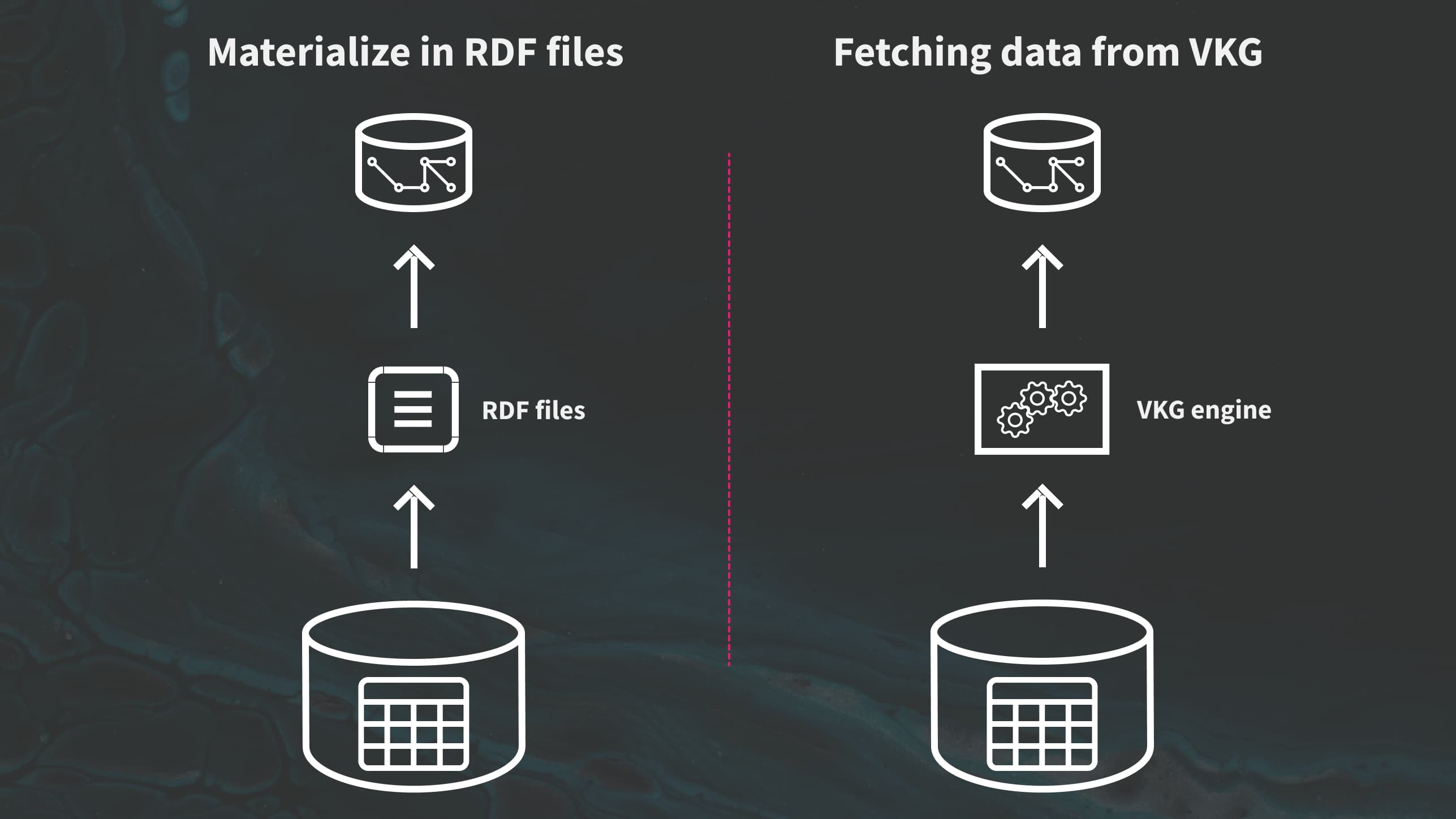
How to materialize data into a graph database using Ontop
Let’s start with the most common way to use materialize with Ontop:
-
Materialize in RDF files and load into a triplestore
For this tutorial, you will need the following prerequisites:
Using the CLI command ontop-materialize (https://ontop-vkg.org/guide/cli#ontop-materialize), you can materialize your KG into one or multiple files. For simplicity, we keep the default option and only materialize it into one file.
./ontop materialize -m mapping.ttl -p credentials.properties -f turtle -o materialized-triples.ttl
After running the command, we have all the content of our KG copied to the file materialized-triples.ttl.
Now we load this file in the triplestore of our choice, in this case, we use GraphDB. This graph database offers several ways to load files. Here, since our file is only 200 MB, we go for the simplest option and load it directly from the UI.
Once this is done, we can query this KG using GraphDB.
-
Deploy a VKG and fetch its content from the graph database
For this second solution, we make use of the concept of KG virtualization, which you can learn more about in this article.
This approach is a more direct solution.
We deploy the KG as a virtual KG first and then query it from the graph database. In this way, you can retrieve the triples and store them locally in the graph database.
Triples are directly streamed to the graph database: no intermediate file storage is involved, making this solution more direct than the previous one.
Going back to our example, instead of using the ontop-materialize CLI command, let’s deploy the KG as a virtual KG using the ontop-endpoint command:
./ontop endpoint -m mapping.ttl -p credentials.properties
Now Ontop is deployed as a SPARQL endpoint available at http://localhost:8080/sparql.
Let’s go now to GraphDB. To fetch and insert all the triples from the VKG exposed by Ontop, we run the following SPARQL INSERT query from GraphDB itself:
INSERT { ?s ?p ?o } WHERE { SERVICE <http://localhost:8080/sparql> { ?s ?p ?o } }This query materializes the same triples as with the first approach.
Which approach to choose for your use case?
If your dataset is not particularly large and a communication channel is easy to set up between the Ontop SPARQL endpoint and the graph database, we recommend solution #2 as it avoids dealing with files and allocating intermediate storage.
If your dataset is very large, you want to use the most efficient loading solution supported by the triplestore, even if it requires more effort to set it up.
Another interesting feature of solution #2, is that it makes it easy to materialize only fragments of the KG, as it just requires adapting the SPARQL query.
This allows for hybrid KGs, where one part is stored in a graph database, and the rest is kept virtual.
Keeping data virtual is particularly advantageous when dealing with large volumes of sensor data that are constantly updated. It makes sense to keep this part of the knowledge graph virtual while storing rich contextual information in the graph database.
What about ontology?
Users familiar with Ontop may have noticed that we didn’t use an ontology in this example.
If you provide an ontology to Ontop, the resulting KG may be significantly larger than the one without due to the reasoning capabilities embedded in Ontop.
As GraphDB also embeds reasoning capabilities, the reasoning can be done later in GraphDB, rather than before at the Ontop. This makes the materialization simpler and faster.
However, if your graph database doesn’t support reasoning, you can rely on Ontop to perform it.
What about mapping?
Any R2RML mapping is supported (read more on the mapping approach here), as well as the Ontop native format (.obda).
You can create these mappings manually or use a specialized platform like Ontopic Suite. The no-code environment allows users to design knowledge graphs, managing large mappings and run virtual graph and semantically enriched SQL databases.
Get a demo access of Ontopic Suite
Ready to create and run virtual knowledge graphs with a no-code approach? Let us help you. Get a demo access:

