Considerations when choosing a Mapping Editor for building a knowledge graph
Let me start with a personal story about how frustrating constructing a knowledge graph can be without a good mapping editor.
In 2014 I entered the world of knowledge graph when joining the Ontop team. A year later, I was invited to give a mapping construction tutorial during a two-day academic workshop dedicated to knowledge graphs in Humanities.
During the first day of the event, I was glad to see that this community had a good understanding of how knowledge graphs can support their work.
And then came the second day of the workshop, the day when we had to put ideas into practice. During my tutorial, I observed that while perfectly understanding and having the best intent to use knowledge graphs, most of the audience struggled with the technicalities knowledge graph construction exposed them to.
My audience had to deal with SQL queries, the mapping syntax and IRIs to name a few. Many typos were made, some of which were hard to spot by the untrained eye.
We spent most of our time on these technical details, and little energy was left to discuss the design choices beyond the proposed modeling, which are far more interesting and valuable aspects of the knowledge graph design.
It was on that second day that I realized that there was a considerable lack of tooling that would hide most of these technicalities and let people focus instead on what matters the most.
Since then, me and colleagues in the Ontop team and later on at Ontopic, began searching for tooling and thinking about how we can make constructing knowledge graphs a better experience for people who don’t want to deal with technicalities but focus on combining the data.
Over the years, we got a more and more precise idea of what support we wanted from a good mapping editor. We observed that existing tools did not fully address our criteria.
Many tools were good at some of the criteria, but none combined all of them. For instance, while some editors would let you write complex mappings, they didn’t visualize data or let you efficiently search. And this became a key motivation for us to create Ontopic Studio.
In this post, we will first give a brief overview of the main approaches adopted by mapping editors, and then you will read about the main things we consider as essential when choosing a mapping editor.

Main approaches followed by mapping editors
I group the mapping editors into the following categories:
- Text editors
- Domain specific languages
- Visual editors
- Form-based editors
Text editors and domain-specific languages
Text editors are the most commonly used.
Users can directly edit the text representation of a mapping language, which can be R2RML or RML, or, most of the time, a syntactic variant of them.
Examples are the Ontop Protégé plugin with the native Ontop format (which was used during my tutorial), the YARRRML editor Matey, and Stardog Studio with the Stardog Native Syntax 2 format (SMS2).
One step further from using a custom mapping language is creating a dedicated Domain Specific Language (DSL). A DSL gives more guidance from the code editor through a more suggestive and precise autocompletion.
The Expressive RDF mapping from Zazuko is the best representative of this category that I know.
And then, there are the two categories that are part of the low-code/no-code movement. The no-code movement aims to minimize the exposure to “code,” which relates to mapping syntax and SQL queries in our context.
Low-code/no-code: visual and form-based editors
Visual editors let users add classes as nodes in a graph diagram and properties as node attributes or edges between the nodes. Database relations or SQL queries are then attached to the node's attributes and edges to specify the mapping.
Examples of this category include RMLEditor, Stardog Designer and Gra.fo
Finally, with form-based editors, users specify their mapping entries using forms, where they can select values like classes, properties, database relations, and columns in menus.
Tools in this category include Eccenca Corporate Memory and Ontopic Studio.
Important things to consider when choosing a mapping editor
-
Keeping the technicalities as low as possible
It is critical to avoid distraction when mapping data. Technicalities too often distract people from what is important.
You should aim at having the most productive interaction with subject matter experts to let their hard-learned knowledge bring value to the knowledge graph.
This is where attention should go. This requires a particular mode of thinking, which is, in my experience, very different from the one needed for handling the technicalities with all the rigorousness they require.
Here are three essential directions for reducing exposure to technicalities:
-
Minimize the need to learn a mapping syntax
Minimize the need to learn a mapping syntax. R2RML is great for interoperability but, in my opinion, it is not something you want to expose mapping designers directly to, as it is verbose and not so easy to teach.
As a response, many dialects exist to make it simpler, but they still require substantial learning. Auto-completion offered by domain-specific languages alleviates the learning effort, but the best options in my view are low-code/no-code approaches which simply hide the mapping syntax.
-
Avoid writing column and table names manually
Typing column and table names manually while respecting the quoting conventions of the underlying system has been proven very error-prone and slows down the mapping construction process, especially when one needs to use an external tool (like a database explorer) to find these names.
It is something at which domain-specific languages and low-code/no-code approaches help.
-
Avoid writing SQL queries
SQL queries are used in the mapping to connect the data in the sources and transform it, usually for data cleaning purposes.
This is a clearly technical task requiring both attention and training. Also, SQL queries are often designed in an external tool, leading to a poorly integrated experience.
But one of the hardest lessons my team and I learned when supporting the Ontop community is that many mapping designers are confused about the role of SQL queries in mappings and tend to make them unnecessarily complex.
These overly complex queries start behaving like black-boxes: they have misunderstood consequences, leading to missing or undesired data in the knowledge graph and preventing many performance optimizations to be applied by the knowledge graph platforms.
Unfortunately, the vast majority of the existing mapping editors tend to over-rely on manually written SQL queries. However, it does not have to be so in most cases, as Ontopic Studio demonstrates, which I consider one of its main achievements.
-
-
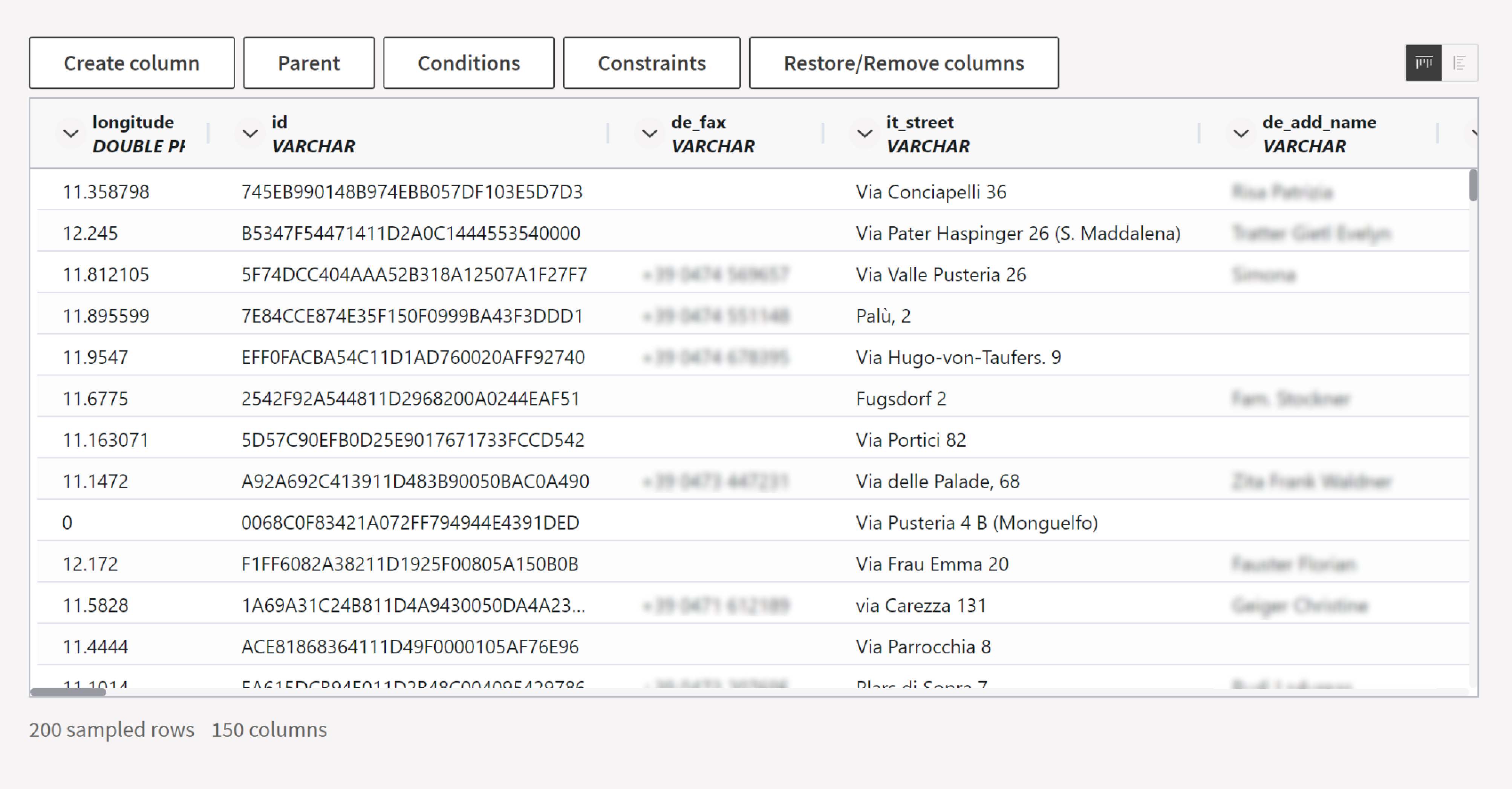
Enabling data preview within the editor
Previewing the data when constructing the mapping is a standard practice, as it helps to understand better what the tables and the columns correspond to (especially when they have ambiguous names), assess their quality, and decide which transformations are needed to clean the data.
Furthermore, some mapping entries directly depend on specific database values: for example, when column “status” equals 2, the row can be mapped to the “Software Engineer” class.
As most mapping editors provide no or poor data preview capabilities, mapping designers typically rely on an external database explorer (like Oracle SQL Developer, MySQL Workbench or DBeaver).
An integrated data preview improves productivity, especially when it comes to mapping entries depending on specific database values.
-
Ensuring interoperability with many platforms, including virtual knowledge graph engines
Mappings should be considered a long-term asset, therefore it is vital to avoid being locked to a specific knowledge graph platform.
Fortunately, standards like R2RML and RML exist to achieve interoperability between platforms.
Last but not least, I encourage you to preserve the possibility of choosing between materializing the KG before loading it in a triplestore, and keeping it virtual by deploying it with a Virtual KG engine.
At the time of writing, R2RML is the only standard that preserves this choice.
-
Scaling to large projects
When evaluating a low-code/no-code tool, it is essential to understand where its biases are and their consequences.
Indeed, many of these tools focus on the simplest cases and cannot cope with the growing complexity of knowledge graphs as more and more data sources are getting included.
A typical problem regards handling identifiers: for instance, does the tool assume that the local primary key of a database table is sufficient for identifying all the instances of a given class?
What happens when a second data source providing different instances of the same class with conflicting local identifiers is added to the knowledge graph? How to handle denormalized data, which is more common that one may think at first glance?
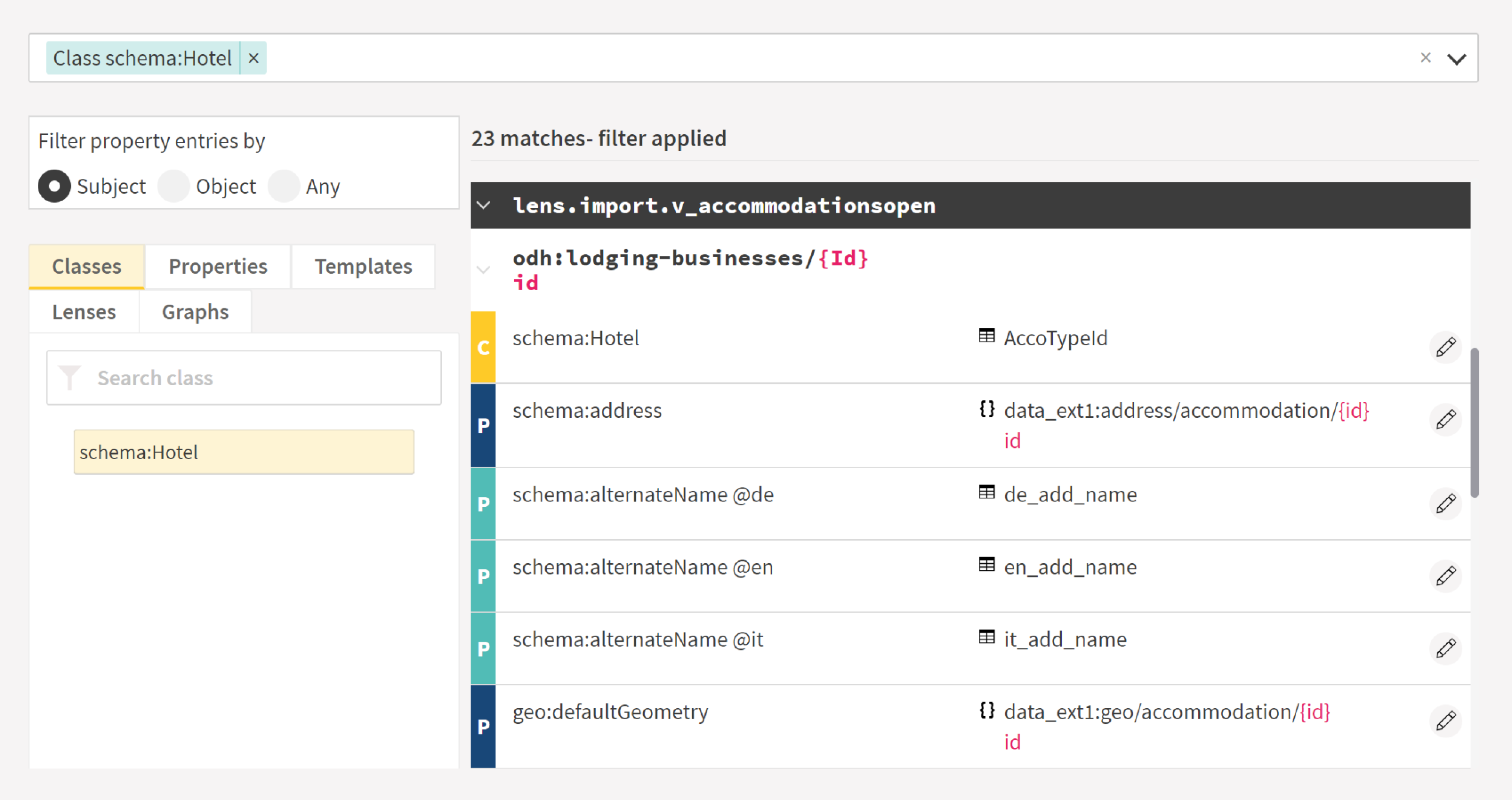
For mapping editors in general, as the mapping gets larger, efficient search becomes critical for finding the relevant mapping entries when a data problem in the knowledge graph is reported or when refactoring is needed.
Plain text search over the text-based mappings can help, but it has clear limitations. It does not allow combining multiple conditions and does not group together mapping entries spread in many files or different areas of large files.
In our own experience, efficient search has been proved essential for preserving productivity as the mapping grows.
In summary, I exposed the four most important criteria we had in mind when designing Ontopic Studio. I invite you to combine them with your own criteria when evaluating different mapping editors for your next knowledge graph project.
In our next post we start to put these considerations in practice by showing you how to create your first mapping pattern in Ontopic Studio.
Have you ever worked with a mapping editor before?
Register for a trial version of Ontopic Studio and start designing your knowledge graph.
Get a demo access of Ontopic Suite
Ready to create and run virtual knowledge graphs with a no-code approach? Let us help you. Get a demo access:

